Statistics for linguist(ic)s blog
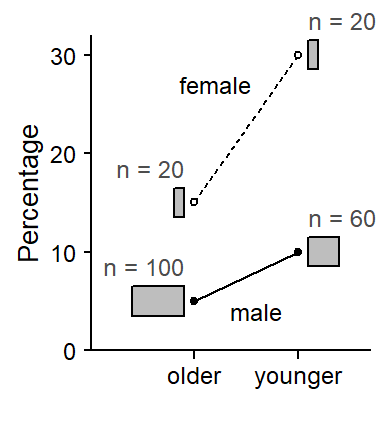
Benchmarking sample-based estimates to population values: Two broad strategies
corpus linguistics
representativeness
regression
bias
imbalance
random forests
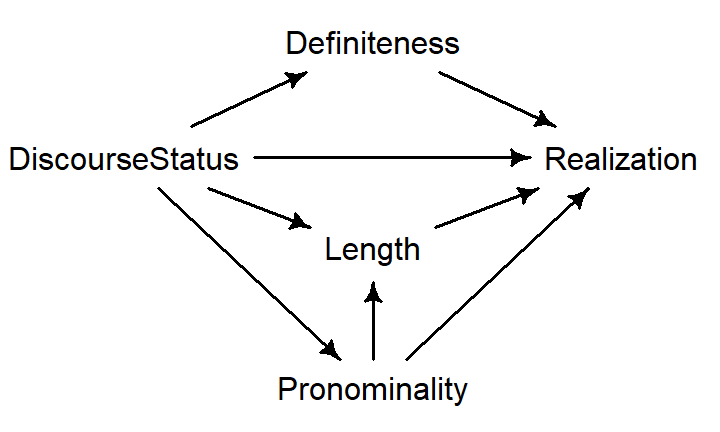
Causally informed regression modeling: The dative alternation
corpus linguistics
regression
bias
causal inference
binary data
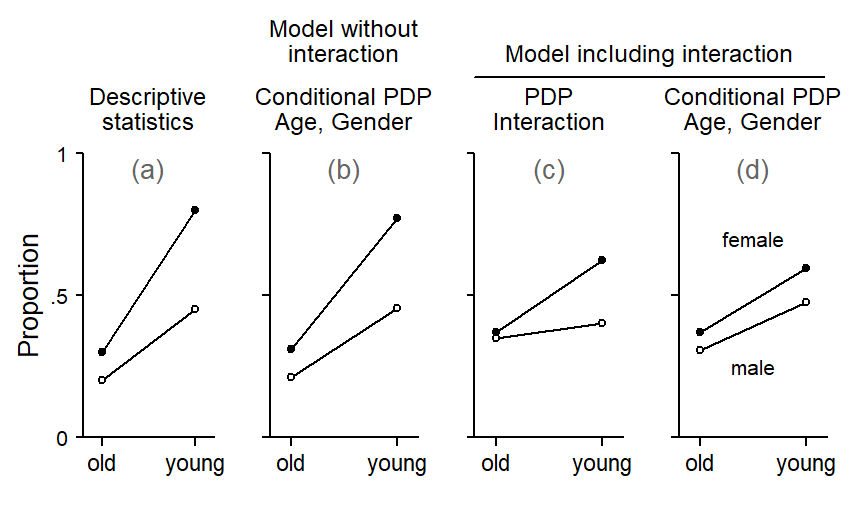
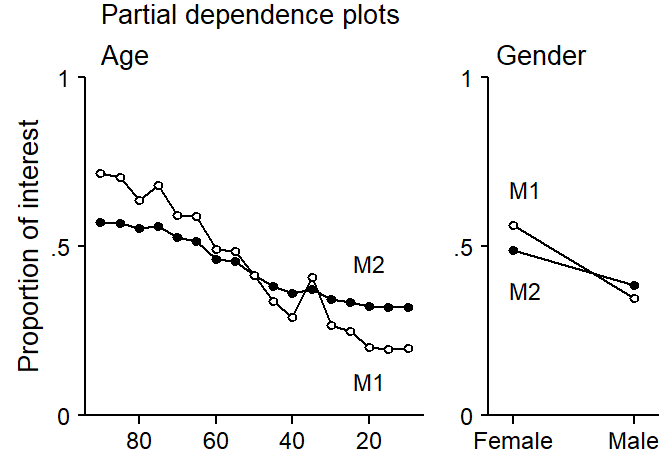
Issues in random-forest modeling: Interaction predictors
corpus linguistics
binary data
random forests
partial dependence plots
Issues in random-forest modeling: Treatment of clustering variables
corpus linguistics
clustered data
bias
binary data
random forests
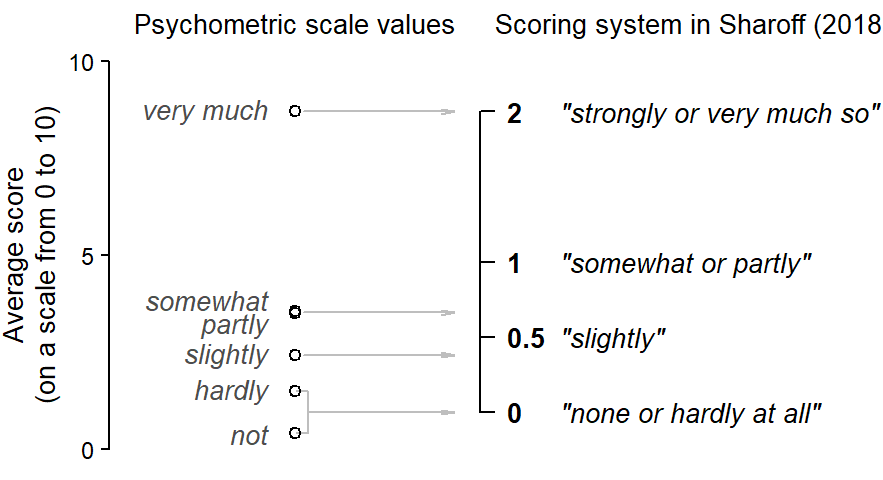
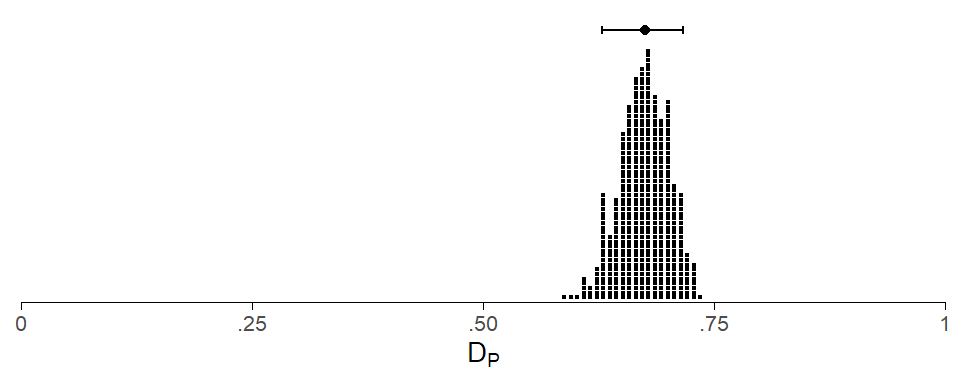
Drawing grouped dot plots in R
data visualization
dot plot
corpus linguistics
frequency data
binary data
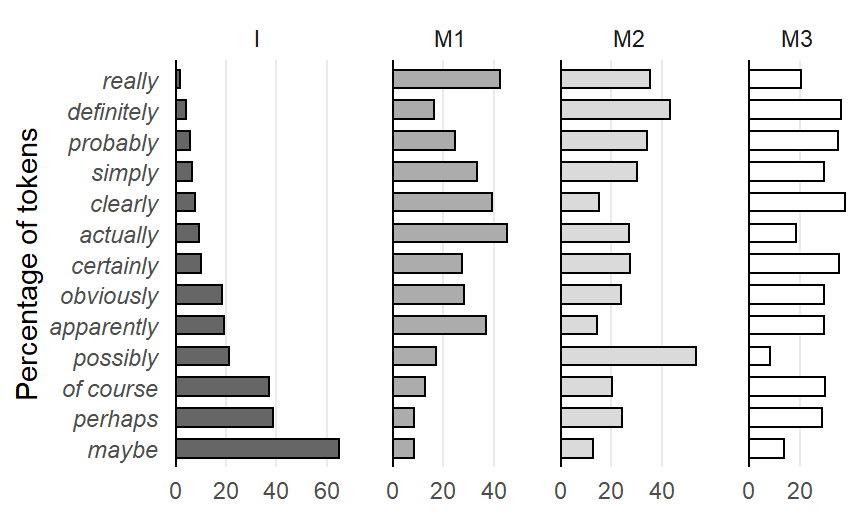
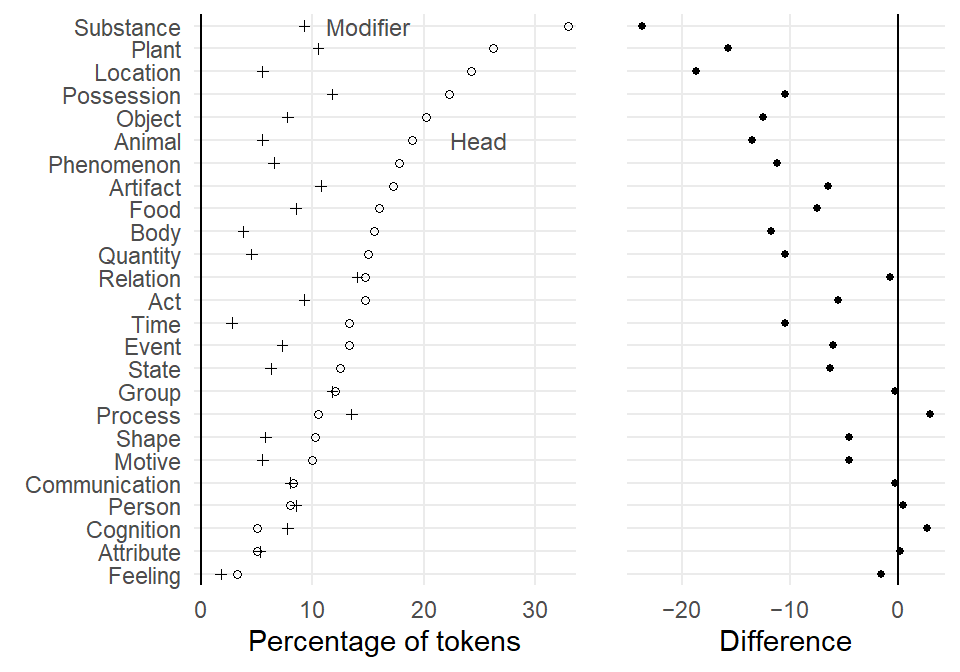
Drawing panel charts in R
data visualization
dot plot
corpus linguistics
frequency data
binary data
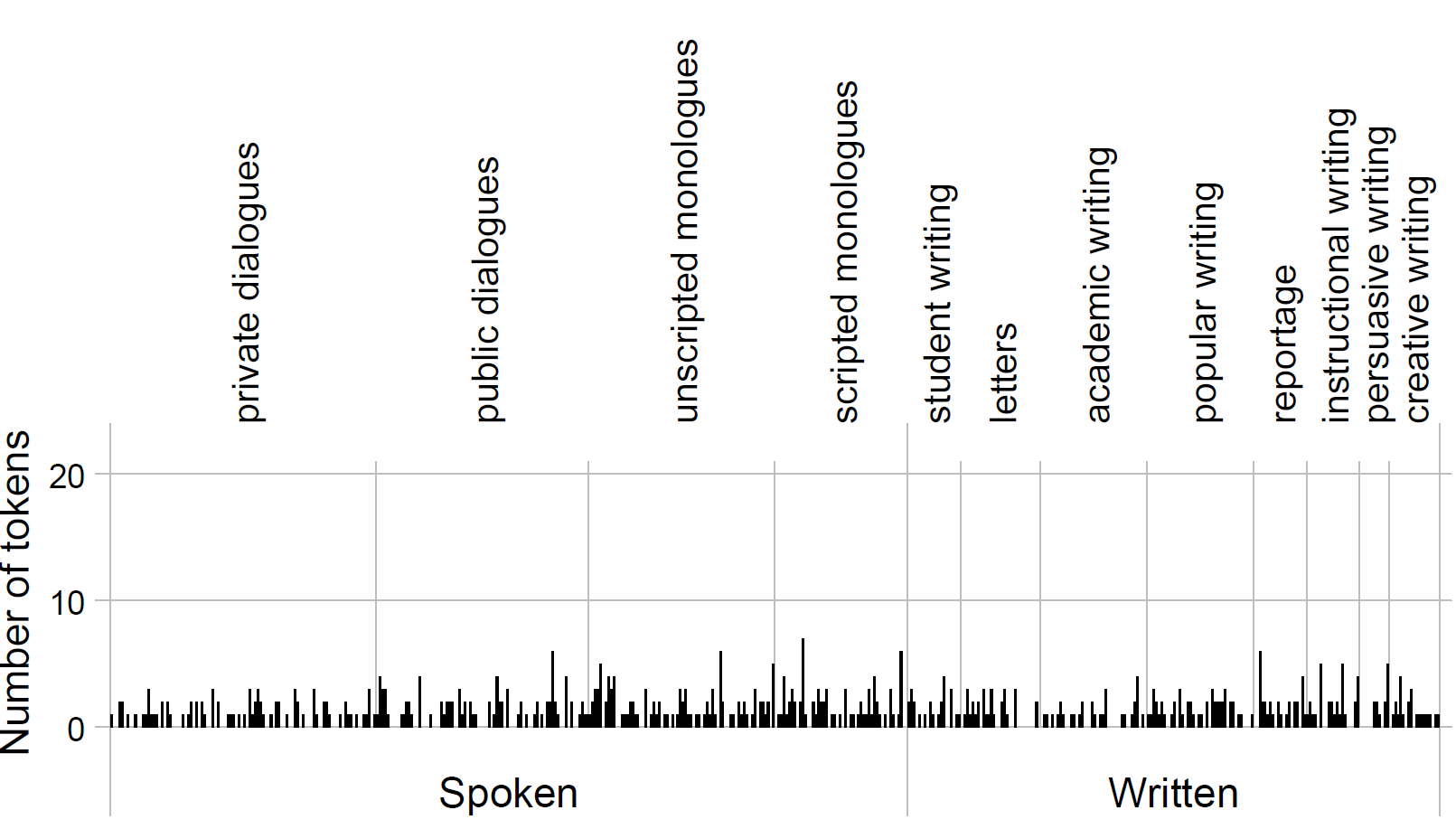
Dispersion: Levels of analysis
corpus linguistics
dispersion
![]()
Tukey’s folded power transformation in R
corpus linguistics
dispersion
data visualization
tlda
binary data
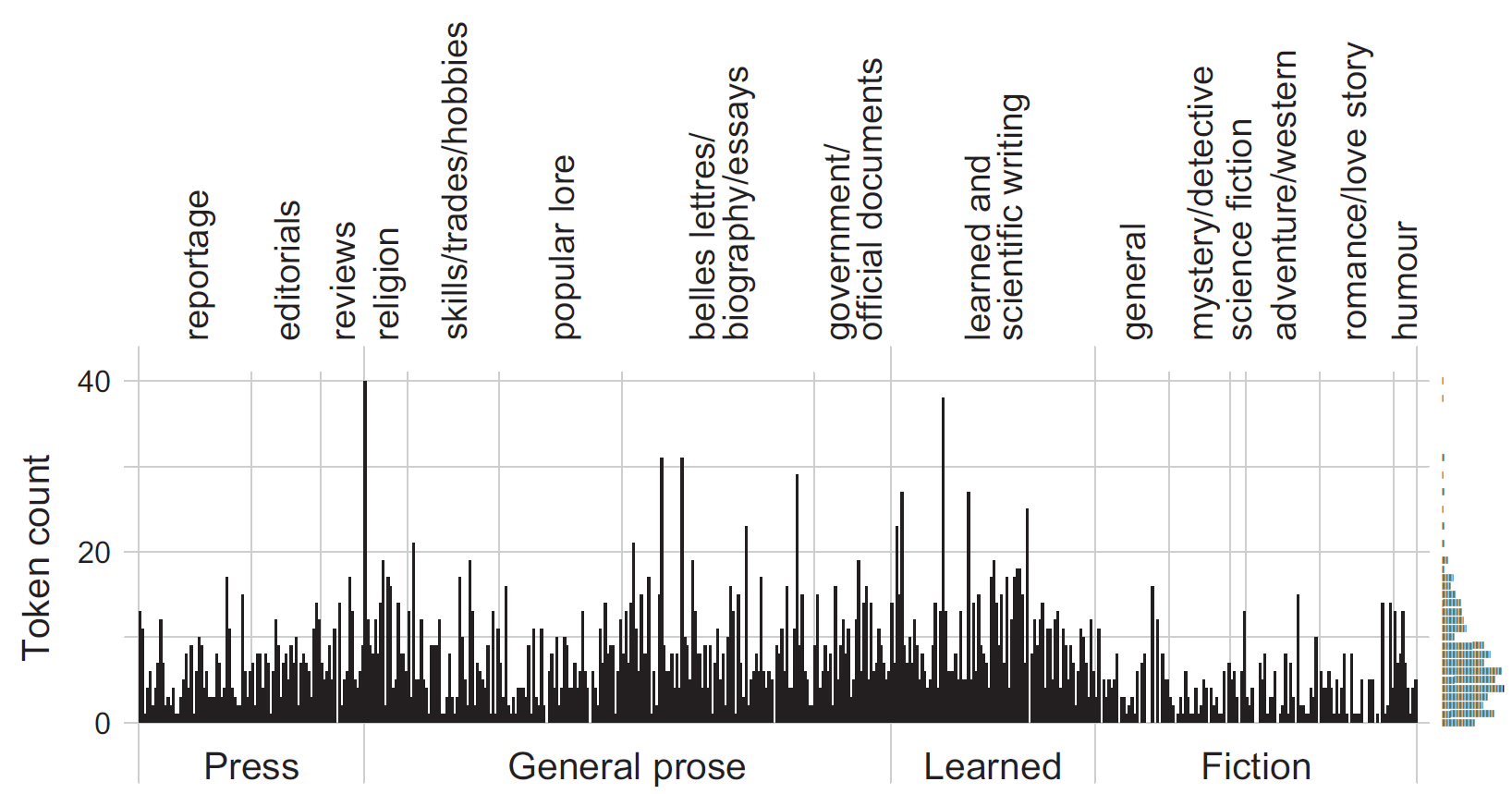
Drawing spike graphs to examine dispersion across text files
corpus linguistics
dispersion
data visualization

Drawing structured dispersion plots in R
corpus linguistics
dispersion
data visualization
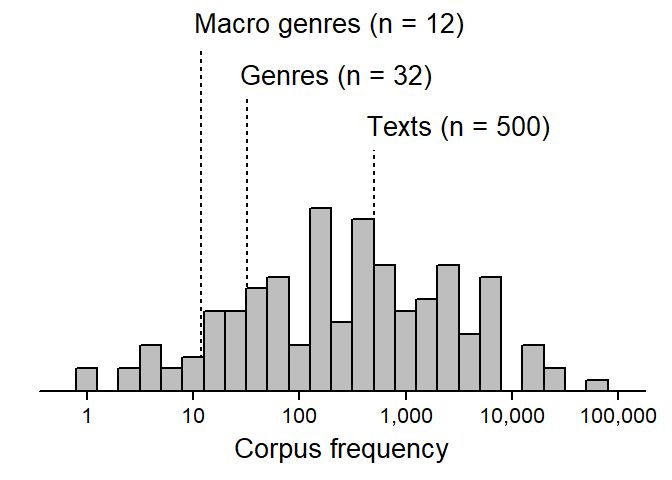
Nelson’s (2025) Poisson-based dispersion measure
corpus linguistics
dispersion
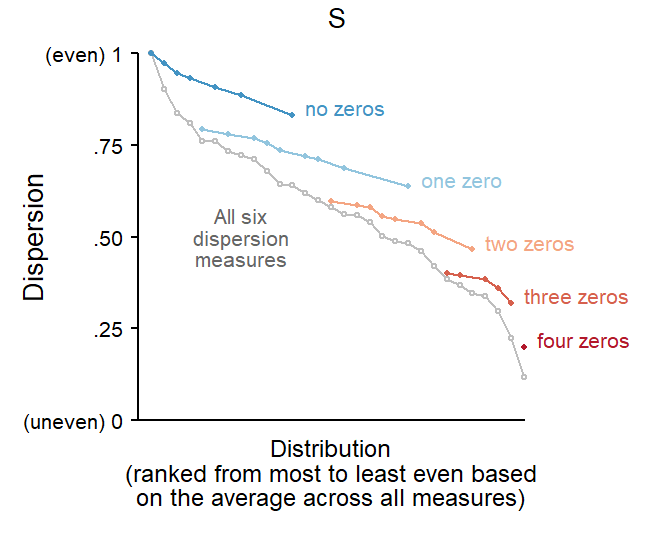
Lyne’s (1985) graphical technique for the evaluation of dispersion measures
corpus linguistics
dispersion
data visualization


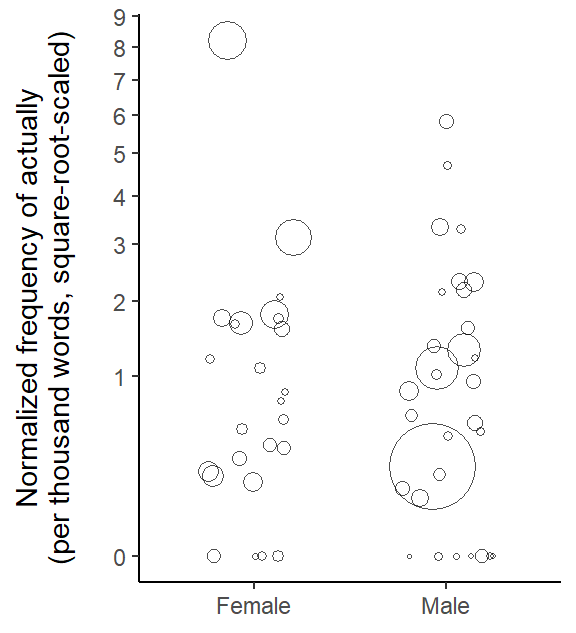
Modeling clustered frequency data II: Texts of disproportionate length
corpus linguistics
regression
clustered data
frequency data
bias
imbalance
negative binomial

Modeling clustered frequency data I: Texts of similar length
corpus linguistics
regression
clustered data
frequency data
negative binomial
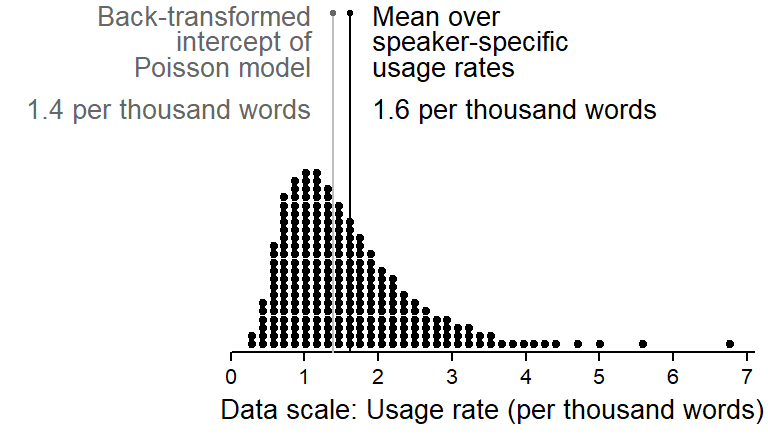
Frequency estimates based on random-intercept Poisson models
corpus linguistics
regression
clustered data
frequency data
negative binomial
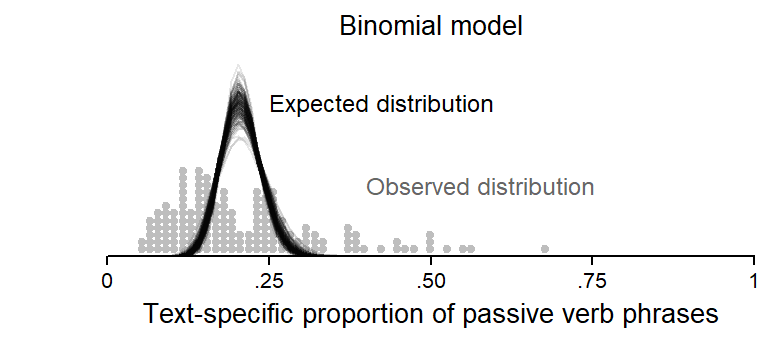
Modeling clustered binomial data
corpus linguistics
regression
clustered data
binary data
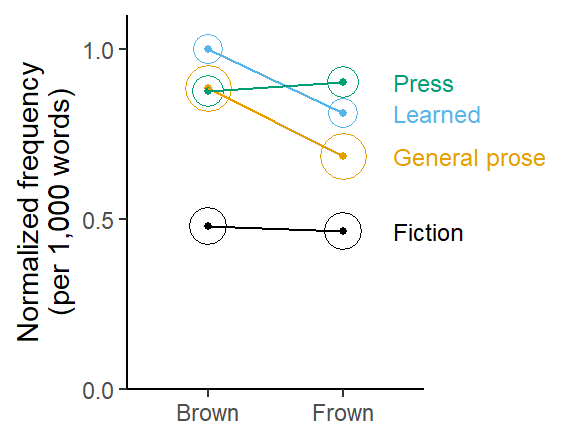
Imbalance across predictor levels affects data summaries
corpus linguistics
replication crisis
regression
bias
imbalance
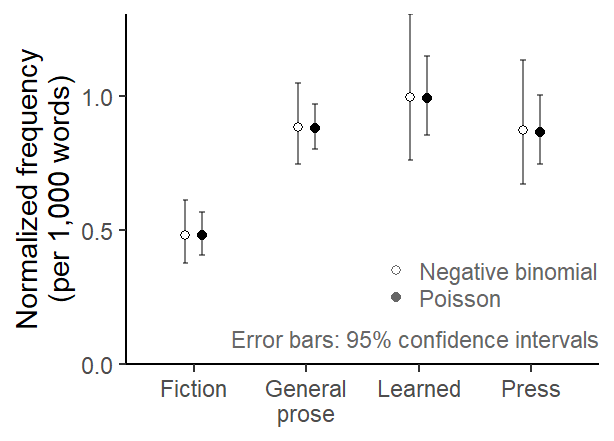
Clustering in the data affects statistical uncertainty intervals
corpus linguistics
replication crisis
regression
clustered data
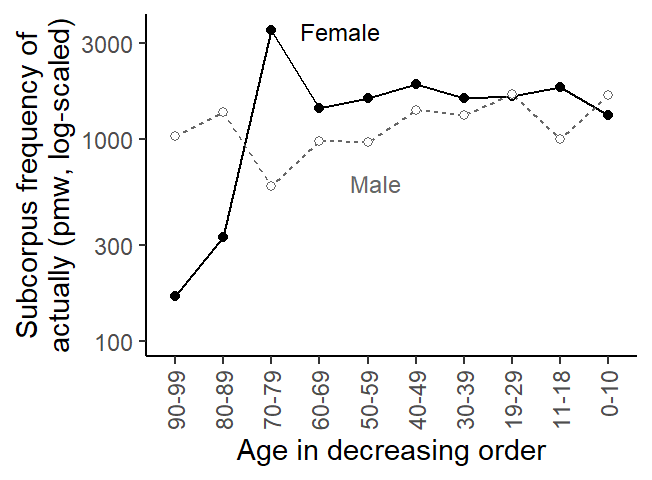
Unbalanced distributions and their consequences: Speakers in the Spoken BNC2014
corpus linguistics
clustered data
negative binomial
clustered data
imbalance
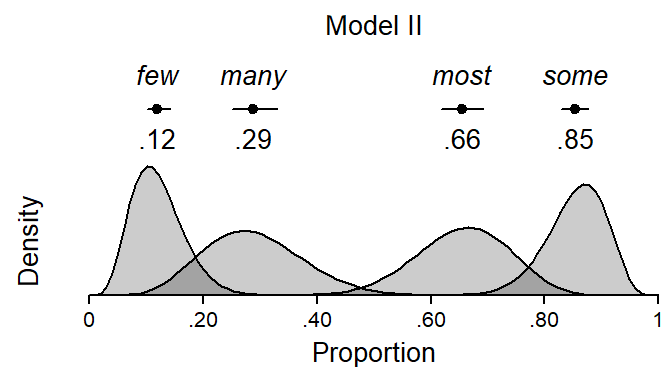
Modeling the interpretation of quantifiers using beta regression
regression
distributional modeling
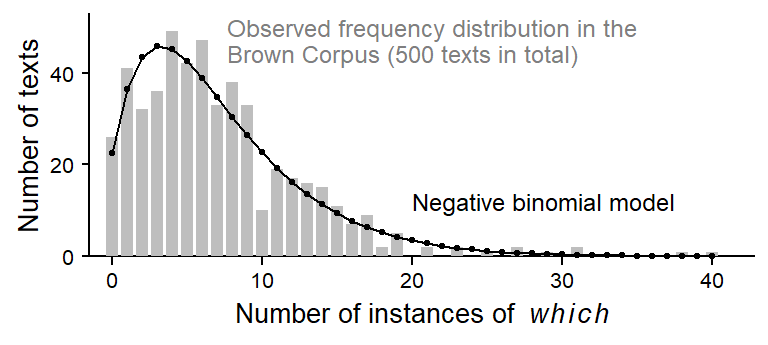
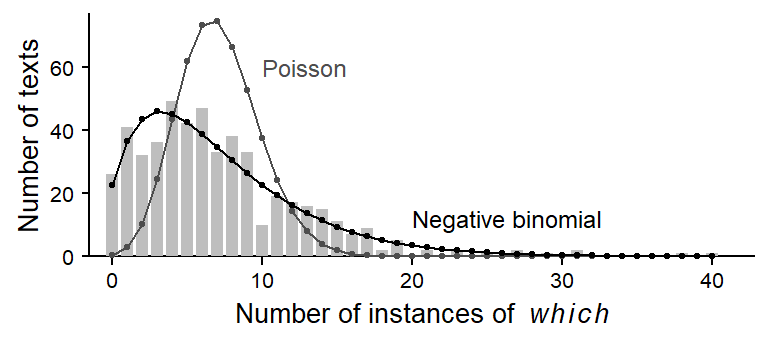
The negative binomial distribution: A visual explanation
corpus linguistics
dispersion
negative binomial
Structured down-sampling: Implementation in R
corpus linguistics
down-sampling
No matching items