PhD workshop
Session 2: Data import/export and data visualization
The dplyr package
- Use the
dplyrpackage (part of thetidyverse) - General approach: Piping
- Pipe operator
|>or%>% - Keyboard shortcut: Ctrl + Shift + M
- Pipe operator
- Perform a sequence (pipeline) of operations on data frames
![]()
Data visualization: Resources
- Use the
ggplot2package (part of thetidyverse) - Healy 2017
- Wickham & Grolemund 2023: Chapter 3 (free online)
- Chang 2023 (free online)
![]()
ggplot2
The way in which ggplot2 works may seem confusing at first. However, it is a very flexible and powerful tool and has become the de-facto standard for adanced data visualization in R. There is a large community of users, which makes it easy to find help online.
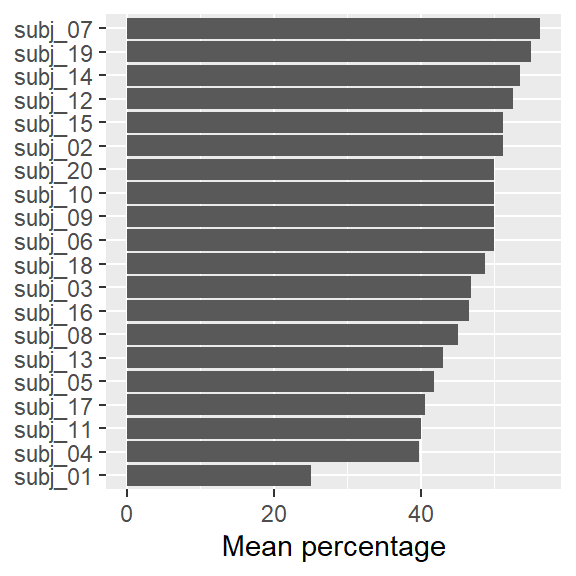
Data visualization: Disagreement data
- Visualize using a dot diagram
Saving graphics
- Use
ggsave()to save graph as PDF - Use
here()to refer to subfolder “figures”
Saving graphs: File format
Always save graphs as PDF files, to have publication-quality images. If you need to insert a graph into a PowerPoint (or Word), use the free software IrfanView: (1) Open the PDF using Adobe Acrobat, (2) Zoom in/out to set the resolution, (3) Make a screenshot, (4) Paste it (Ctrl. + V) into IrfanView, (5) cut out the graph (Ctrl. + C), and (6) paste it (Ctrl. + V) into PowerPoint/Word.

![]()
![]()
ggplot2: Dot plot
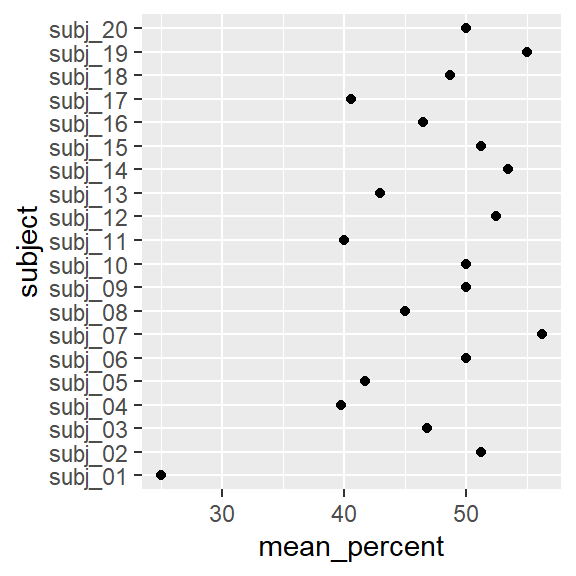
ggplot2: Dot plot
- Order

ggplot2: Dot plot
- Change axis labels
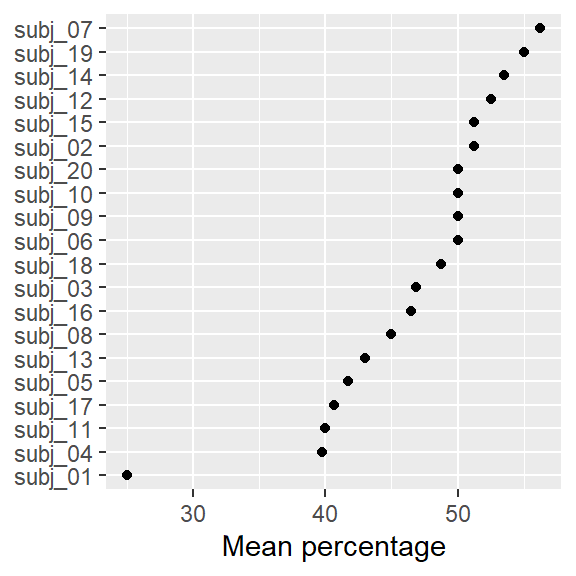
ggplot2: Dot plot
- Change into bar chart